
Featuretools is a fantastic python package for automated feature engineering. It can automatically generate features from secondary datasets which can then be used in machine learning models. In this post we’ll see how automated feature engineering with Featuretools works, and how to run it on complex multi-table datsets!
Outline
- Automated Feature Engineering
- Deep Feature Synthesis
- Using Featuretools
- Predictions from Generated Features
- Running out of Memory
Automated Feature Engineering
What do I mean by “automated feature engineering” and how is it useful? When building predictive models, we need to have training examples which have some set of features. For most machine learning algorithms (though of course not all of them), this training set needs to take the form of a table or matrix, where each row corresponds to a single training example or observation, and each column corresponds to a different feature. For example, suppose we’re trying to predict how likely loan applicants are to successfully repay their loans. In this case, our data table will have a row for each applicant, and a column for each “feature” of the applicants, such as their income, their current level of credit, their age, etc.
Unfortunately, in most applications the data isn’t quite as simple as just one table. We’ll likely have additional data stored in other tables! To continue with the loan repayment prediction example, we could have a separate table which stores the monthly balances of applicants on their other loans, and another separate table with the credit card accounts for each applicant, and yet another table with the credit card activity for each of those accounts, and so on.

In order to build a predictive model, we need to “engineer” features from data in those secondary tables. These engineered features can then be added to our main data table, which we can then use to train the predictive model. For example, we could compute the number of credit card accounts for each applicant, and add that as a feature to our primary data table; we could compute the balance across each applicant’s credit cards, and add that to the primary data table; we could also compute the balance to available credit ratio and add that as a feature; etc.
With complicated (read: real-life) datasets, the number of features that we could engineer becomes very large, and the task of manually engineering all these features becomes extremely time-intensive. The Featuretoools package automates this process by automatically generating features for our primary data table from information in secondary data sources.
Deep Feature Synthesis
Featuretools uses a process they call “deep feature synthesis” to generate top-level features from secondary datasets. For each secondary table, the child table is merged with the parent table on the column which joins them (usually an ID or something). Raw features can be transformed according to transform primitives like month (which transforms a datetime into a month, or cum_sum which transforms a value to the cumulative sum of elements in that aggregation bin. Then, features are built from “aggregation primitives”, such as mean, sum, max, etc, which aggregate potentially multiple entries in the child table to a single feature in the parent dataset. This feature generation process is repeated recursively until we have a single table (the primary table) with features generated from child and sub-child (etc) tables.
Using Featuretools
To show how Featuretools works, we’ll be using it on the Home Credit Group Default Risk dataset. This dataset contains information about individuals applying for loans with Home Credit Group, a consumer lender specializing in loans to individuals with little credit history. Home Credit Group hopes to be able to predict how likely an applicant is to default on their loan, in order to decide whether a given loan plan is good for a specific applicant (or whether to suggest a different payment schedule).
The dataset contains multiple tables which relate to one another in some way. Below is a diagram which shows each data table, the information it contains, and how each table is related to each other table.
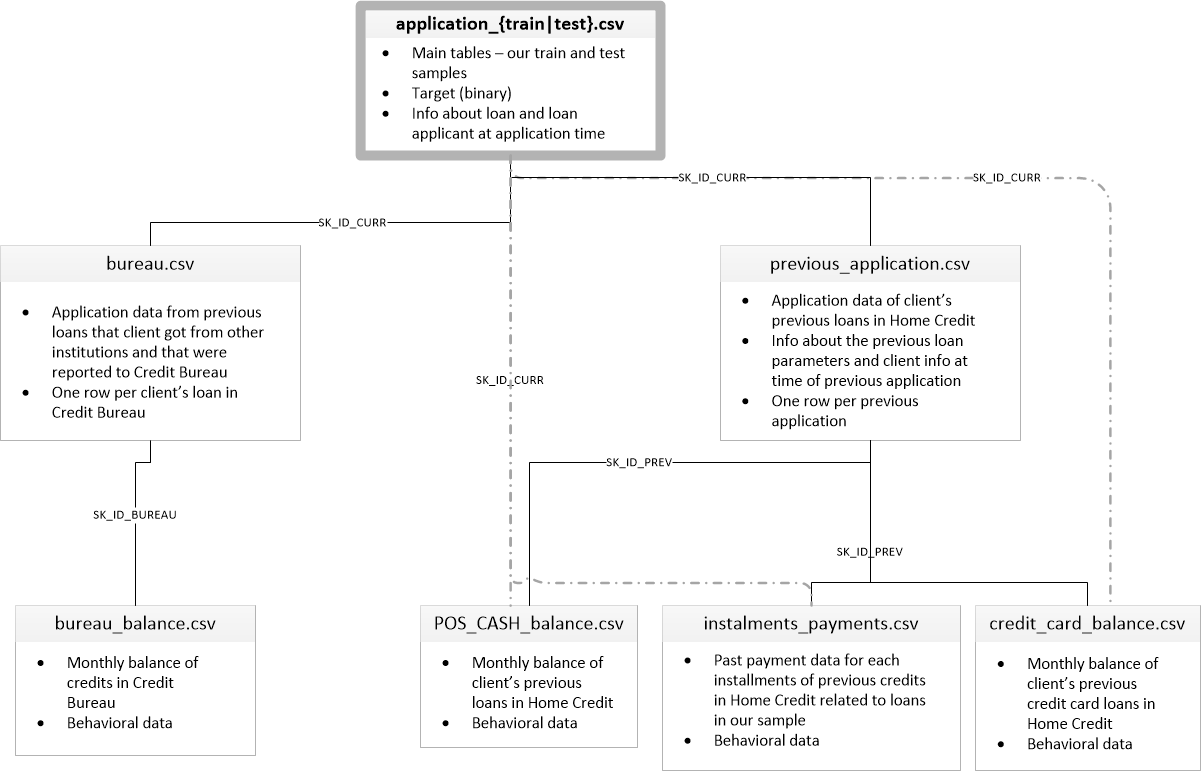
The primary tables (application_train.csv and application_test.csv) have information on each of the loan applications, where each row corresponds to a single application. The train table has information about whether that applicant ended up defaulting on their loan, while the test table does not (because those are the applications we’ll be testing our predictive model on). The other tables contain information about other loans (either at other institutions, in the bureau.csv and bureau_balance.csv tables, or previous loans with Home Credit, in previous_applications.csv, POS_CASH_balance.csv, instalments_payments.csv, and credit_card_balance.csv).
What are the relationships between these tables? The value in the SK_ID_CURR column of the application_*.csv and bureau.csv tables identify the applicant. That is, to combine the two tables into a single table, we could merge on SK_ID_CURR. Similarly, the SK_ID_BUREAU column in bureau.csv and bureau_balance.csv identifies the applicant, though in this case there can be multiple entries in bureau_balance.csv for a single applicant. The text in the line connecting the tables in the diagram above shows what column two tables can be merged on.
We could manually go through all these databases and construct features based on them, but this would entail not just a lot of manual work, but a lot of design decisions. For example, should we construct a feature which corresponds to the maximum amount of credit the applicant has ever carried? Or the average amount of credit? Or the monthly median credit? Should we construct a feature for how many payments the applicant has made, or how regular their payments are, or when they make their payments, etc, etc, etc?
Featuretools allows us to define our datasets, the relationships between our datasets, and automatically extracts features from child datasets into parent datasets using deep feature synthesis. We’ll use Featuretools to generate features from the data in the secondary tables in the Home Credit Group dataset, and keep features which are informative.
First let’s load the packages we need.
# Load packages
import numpy as np
import pandas as pd
import featuretools as ft
from featuretools import selection
from sklearn.preprocessing import RobustScaler
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.calibration import CalibratedClassifierCV
from lightgbm import LGBMClassifier
We’ll use pandas to load the data.
# Load applications data
train = pd.read_csv('application_train.csv')
test = pd.read_csv('application_test.csv')
bureau = pd.read_csv('bureau.csv')
bureau_balance = pd.read_csv('bureau_balance.csv')
cash_balance = pd.read_csv('POS_CASH_balance.csv')
card_balance = pd.read_csv('credit_card_balance.csv')
prev_app = pd.read_csv('previous_application.csv')
payments = pd.read_csv('installments_payments.csv')
To ensure that featuretools creates the same features for the test set as for the training set, we’ll merge the two tables, but add a column which indicates whether each row is a test or training
# Merge application data
train['Test'] = False
test['Test'] = True
test['TARGET'] = np.nan
app = train.append(test, ignore_index=True, sort=False)
Now we can take a look at the data in the main table.
app.sample(10)
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | AMT_GOODS_PRICE | NAME_TYPE_SUITE | NAME_INCOME_TYPE | NAME_EDUCATION_TYPE | NAME_FAMILY_STATUS | NAME_HOUSING_TYPE | REGION_POPULATION_RELATIVE | DAYS_BIRTH | DAYS_EMPLOYED | DAYS_REGISTRATION | DAYS_ID_PUBLISH | OWN_CAR_AGE | FLAG_MOBIL | FLAG_EMP_PHONE | FLAG_WORK_PHONE | FLAG_CONT_MOBILE | FLAG_PHONE | FLAG_EMAIL | OCCUPATION_TYPE | CNT_FAM_MEMBERS | REGION_RATING_CLIENT | REGION_RATING_CLIENT_W_CITY | WEEKDAY_APPR_PROCESS_START | HOUR_APPR_PROCESS_START | REG_REGION_NOT_LIVE_REGION | REG_REGION_NOT_WORK_REGION | LIVE_REGION_NOT_WORK_REGION | REG_CITY_NOT_LIVE_CITY | REG_CITY_NOT_WORK_CITY | LIVE_CITY_NOT_WORK_CITY | ... | LIVINGAREA_MEDI | NONLIVINGAPARTMENTS_MEDI | NONLIVINGAREA_MEDI | FONDKAPREMONT_MODE | HOUSETYPE_MODE | TOTALAREA_MODE | WALLSMATERIAL_MODE | EMERGENCYSTATE_MODE | OBS_30_CNT_SOCIAL_CIRCLE | DEF_30_CNT_SOCIAL_CIRCLE | OBS_60_CNT_SOCIAL_CIRCLE | DEF_60_CNT_SOCIAL_CIRCLE | DAYS_LAST_PHONE_CHANGE | FLAG_DOCUMENT_2 | FLAG_DOCUMENT_3 | FLAG_DOCUMENT_4 | FLAG_DOCUMENT_5 | FLAG_DOCUMENT_6 | FLAG_DOCUMENT_7 | FLAG_DOCUMENT_8 | FLAG_DOCUMENT_9 | FLAG_DOCUMENT_10 | FLAG_DOCUMENT_11 | FLAG_DOCUMENT_12 | FLAG_DOCUMENT_13 | FLAG_DOCUMENT_14 | FLAG_DOCUMENT_15 | FLAG_DOCUMENT_16 | FLAG_DOCUMENT_17 | FLAG_DOCUMENT_18 | FLAG_DOCUMENT_19 | FLAG_DOCUMENT_20 | FLAG_DOCUMENT_21 | AMT_REQ_CREDIT_BUREAU_HOUR | AMT_REQ_CREDIT_BUREAU_DAY | AMT_REQ_CREDIT_BUREAU_WEEK | AMT_REQ_CREDIT_BUREAU_MON | AMT_REQ_CREDIT_BUREAU_QRT | AMT_REQ_CREDIT_BUREAU_YEAR | Test | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 118496 | 237410 | 1.0 | Revolving loans | M | N | N | 0 | 157500.0 | 247500.0 | 12375.0 | 247500.0 | Unaccompanied | Commercial associate | Secondary / secondary special | Civil marriage | House / apartment | 0.018209 | -16608 | -898 | -26.0 | -119 | NaN | 1 | 1 | 0 | 1 | 0 | 0 | Low-skill Laborers | 2.0 | 3 | 3 | THURSDAY | 15 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.0548 | NaN | 0.0000 | NaN | block of flats | 0.0467 | Panel | No | 4.0 | 1.0 | 4.0 | 1.0 | -1007.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | False |
| 254313 | 394281 | 0.0 | Cash loans | F | N | Y | 0 | 238500.0 | 526491.0 | 22306.5 | 454500.0 | Unaccompanied | Working | Higher education | Civil marriage | House / apartment | 0.072508 | -15175 | -1127 | -9211.0 | -3148 | NaN | 1 | 1 | 1 | 1 | 1 | 0 | Private service staff | 2.0 | 1 | 1 | THURSDAY | 16 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.1456 | 0.0000 | 0.0002 | reg oper account | block of flats | 0.3877 | Panel | No | 0.0 | 0.0 | 0.0 | 0.0 | -1426.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | False |
| 48875 | 156605 | 0.0 | Cash loans | F | N | N | 0 | 67500.0 | 306000.0 | 13608.0 | 306000.0 | Unaccompanied | Working | Higher education | Married | House / apartment | 0.025164 | -11140 | -1712 | -821.0 | -845 | NaN | 1 | 1 | 1 | 1 | 1 | 0 | NaN | 2.0 | 2 | 2 | TUESDAY | 11 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.0653 | NaN | 0.0000 | reg oper account | block of flats | 0.0556 | Panel | No | 0.0 | 0.0 | 0.0 | 0.0 | -1000.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 3.0 | False |
| 52138 | 160377 | 0.0 | Cash loans | F | N | Y | 0 | 180000.0 | 296280.0 | 19930.5 | 225000.0 | Unaccompanied | Working | Secondary / secondary special | Married | House / apartment | 0.030755 | -9932 | -1871 | -2032.0 | -469 | NaN | 1 | 1 | 0 | 1 | 0 | 0 | Managers | 2.0 | 2 | 2 | WEDNESDAY | 15 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.0791 | 0.2717 | 0.0000 | reg oper account | block of flats | 0.0752 | Stone, brick | No | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | False |
| 297167 | 444284 | 0.0 | Cash loans | M | Y | Y | 0 | 45000.0 | 152820.0 | 9949.5 | 135000.0 | Unaccompanied | Working | Secondary / secondary special | Separated | House / apartment | 0.009549 | -16817 | -2620 | -2603.0 | -157 | 15.0 | 1 | 1 | 0 | 1 | 0 | 0 | Drivers | 1.0 | 2 | 2 | TUESDAY | 14 | 0 | 0 | 0 | 1 | 1 | 0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | 0.0 | 0.0 | 0.0 | -1714.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | False |
| 146029 | 269323 | 0.0 | Cash loans | M | Y | N | 0 | 202500.0 | 521280.0 | 28278.0 | 450000.0 | Unaccompanied | Working | Lower secondary | Single / not married | House / apartment | 0.019689 | -8448 | -1125 | -3276.0 | -1115 | 8.0 | 1 | 1 | 1 | 1 | 0 | 0 | Drivers | 1.0 | 2 | 2 | MONDAY | 12 | 0 | 0 | 0 | 1 | 1 | 0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 8.0 | 0.0 | 8.0 | 0.0 | -536.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | False |
| 236319 | 373722 | 0.0 | Cash loans | M | N | N | 0 | 224802.0 | 1633473.0 | 43087.5 | 1363500.0 | Unaccompanied | Working | Incomplete higher | Single / not married | House / apartment | 0.022800 | -8995 | -508 | -24.0 | -1673 | NaN | 1 | 1 | 1 | 1 | 1 | 0 | Laborers | 1.0 | 2 | 2 | WEDNESDAY | 13 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.3271 | 0.0039 | 0.0087 | org spec account | block of flats | 0.2932 | Panel | No | 1.0 | 0.0 | 1.0 | 0.0 | -2.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | False |
| 327884 | 247902 | NaN | Cash loans | M | N | Y | 0 | 202500.0 | 746280.0 | 59094.0 | 675000.0 | Unaccompanied | Commercial associate | Secondary / secondary special | Single / not married | House / apartment | 0.025164 | -16345 | -401 | -168.0 | -5308 | NaN | 1 | 1 | 0 | 1 | 0 | 0 | Laborers | 1.0 | 2 | 2 | THURSDAY | 8 | 0 | 0 | 0 | 0 | 0 | 0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 4.0 | True |
| 108336 | 225672 | 0.0 | Cash loans | F | Y | Y | 0 | 360000.0 | 2250000.0 | 59485.5 | 2250000.0 | Unaccompanied | Pensioner | Higher education | Separated | House / apartment | 0.026392 | -22804 | 365243 | -4600.0 | -1567 | 2.0 | 1 | 0 | 0 | 1 | 0 | 0 | NaN | 1.0 | 2 | 2 | THURSDAY | 18 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.4250 | NaN | 0.4709 | NaN | block of flats | 0.1515 | Monolithic | No | 3.0 | 0.0 | 3.0 | 0.0 | -649.0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | False |
| 160040 | 285530 | 0.0 | Cash loans | F | N | N | 2 | 135000.0 | 178290.0 | 14215.5 | 157500.0 | Unaccompanied | Commercial associate | Incomplete higher | Married | House / apartment | 0.035792 | -13106 | -105 | -1435.0 | -5560 | NaN | 1 | 1 | 0 | 1 | 1 | 0 | Managers | 4.0 | 2 | 2 | FRIDAY | 15 | 0 | 0 | 0 | 0 | 0 | 0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | 1.0 | 1.0 | 1.0 | -1344.0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 4.0 | False |
The first step in using Featuretools is to define the “entities”, each of which is one data file or table, and the columns along which they are indexed. We’ll first create an EntitySet, which is, obviously, a set of entities or tables.
# Create an entity set
es = ft.EntitySet(id='applications')
Now we can add tables to this entity set. We’ll define the datatype of each column (variable) in the table using a dictionary, and pass that to Featuretools’ entity_from_dataframe function.
# Add dataframe to entityset
es = es.entity_from_dataframe(entity_id='applications',
dataframe=app,
index='SK_ID_CURR')
We can view our entity set so far,
es
Entityset: applications
Entities:
applications [Rows: 356255, Columns: 123]
Relationships:
No relationships
And the datatypes of each column in the applications dataframe.
es['applications']
Entity: applications
Variables:
SK_ID_CURR (dtype: index)
TARGET (dtype: numeric)
NAME_CONTRACT_TYPE (dtype: categorical)
CODE_GENDER (dtype: categorical)
FLAG_OWN_CAR (dtype: categorical)
FLAG_OWN_REALTY (dtype: categorical)
CNT_CHILDREN (dtype: numeric)
AMT_INCOME_TOTAL (dtype: numeric)
AMT_CREDIT (dtype: numeric)
AMT_ANNUITY (dtype: numeric)
AMT_GOODS_PRICE (dtype: numeric)
NAME_TYPE_SUITE (dtype: categorical)
NAME_INCOME_TYPE (dtype: categorical)
NAME_EDUCATION_TYPE (dtype: categorical)
NAME_FAMILY_STATUS (dtype: categorical)
NAME_HOUSING_TYPE (dtype: categorical)
REGION_POPULATION_RELATIVE (dtype: numeric)
DAYS_BIRTH (dtype: numeric)
DAYS_EMPLOYED (dtype: numeric)
DAYS_REGISTRATION (dtype: numeric)
DAYS_ID_PUBLISH (dtype: numeric)
OWN_CAR_AGE (dtype: numeric)
FLAG_MOBIL (dtype: numeric)
FLAG_EMP_PHONE (dtype: numeric)
FLAG_WORK_PHONE (dtype: numeric)
FLAG_CONT_MOBILE (dtype: numeric)
FLAG_PHONE (dtype: numeric)
FLAG_EMAIL (dtype: numeric)
OCCUPATION_TYPE (dtype: categorical)
CNT_FAM_MEMBERS (dtype: numeric)
REGION_RATING_CLIENT (dtype: numeric)
REGION_RATING_CLIENT_W_CITY (dtype: numeric)
WEEKDAY_APPR_PROCESS_START (dtype: categorical)
HOUR_APPR_PROCESS_START (dtype: numeric)
REG_REGION_NOT_LIVE_REGION (dtype: numeric)
REG_REGION_NOT_WORK_REGION (dtype: numeric)
LIVE_REGION_NOT_WORK_REGION (dtype: numeric)
REG_CITY_NOT_LIVE_CITY (dtype: numeric)
REG_CITY_NOT_WORK_CITY (dtype: numeric)
LIVE_CITY_NOT_WORK_CITY (dtype: numeric)
ORGANIZATION_TYPE (dtype: categorical)
EXT_SOURCE_1 (dtype: numeric)
EXT_SOURCE_2 (dtype: numeric)
EXT_SOURCE_3 (dtype: numeric)
APARTMENTS_AVG (dtype: numeric)
BASEMENTAREA_AVG (dtype: numeric)
YEARS_BEGINEXPLUATATION_AVG (dtype: numeric)
YEARS_BUILD_AVG (dtype: numeric)
COMMONAREA_AVG (dtype: numeric)
ELEVATORS_AVG (dtype: numeric)
ENTRANCES_AVG (dtype: numeric)
FLOORSMAX_AVG (dtype: numeric)
FLOORSMIN_AVG (dtype: numeric)
LANDAREA_AVG (dtype: numeric)
LIVINGAPARTMENTS_AVG (dtype: numeric)
LIVINGAREA_AVG (dtype: numeric)
NONLIVINGAPARTMENTS_AVG (dtype: numeric)
NONLIVINGAREA_AVG (dtype: numeric)
APARTMENTS_MODE (dtype: numeric)
BASEMENTAREA_MODE (dtype: numeric)
YEARS_BEGINEXPLUATATION_MODE (dtype: numeric)
YEARS_BUILD_MODE (dtype: numeric)
COMMONAREA_MODE (dtype: numeric)
ELEVATORS_MODE (dtype: numeric)
ENTRANCES_MODE (dtype: numeric)
FLOORSMAX_MODE (dtype: numeric)
FLOORSMIN_MODE (dtype: numeric)
LANDAREA_MODE (dtype: numeric)
LIVINGAPARTMENTS_MODE (dtype: numeric)
LIVINGAREA_MODE (dtype: numeric)
NONLIVINGAPARTMENTS_MODE (dtype: numeric)
NONLIVINGAREA_MODE (dtype: numeric)
APARTMENTS_MEDI (dtype: numeric)
BASEMENTAREA_MEDI (dtype: numeric)
YEARS_BEGINEXPLUATATION_MEDI (dtype: numeric)
YEARS_BUILD_MEDI (dtype: numeric)
COMMONAREA_MEDI (dtype: numeric)
ELEVATORS_MEDI (dtype: numeric)
ENTRANCES_MEDI (dtype: numeric)
FLOORSMAX_MEDI (dtype: numeric)
FLOORSMIN_MEDI (dtype: numeric)
LANDAREA_MEDI (dtype: numeric)
LIVINGAPARTMENTS_MEDI (dtype: numeric)
LIVINGAREA_MEDI (dtype: numeric)
NONLIVINGAPARTMENTS_MEDI (dtype: numeric)
NONLIVINGAREA_MEDI (dtype: numeric)
FONDKAPREMONT_MODE (dtype: categorical)
HOUSETYPE_MODE (dtype: categorical)
TOTALAREA_MODE (dtype: numeric)
WALLSMATERIAL_MODE (dtype: categorical)
EMERGENCYSTATE_MODE (dtype: categorical)
OBS_30_CNT_SOCIAL_CIRCLE (dtype: numeric)
DEF_30_CNT_SOCIAL_CIRCLE (dtype: numeric)
OBS_60_CNT_SOCIAL_CIRCLE (dtype: numeric)
DEF_60_CNT_SOCIAL_CIRCLE (dtype: numeric)
DAYS_LAST_PHONE_CHANGE (dtype: numeric)
FLAG_DOCUMENT_2 (dtype: numeric)
FLAG_DOCUMENT_3 (dtype: numeric)
FLAG_DOCUMENT_4 (dtype: numeric)
FLAG_DOCUMENT_5 (dtype: numeric)
FLAG_DOCUMENT_6 (dtype: numeric)
FLAG_DOCUMENT_7 (dtype: numeric)
FLAG_DOCUMENT_8 (dtype: numeric)
FLAG_DOCUMENT_9 (dtype: numeric)
FLAG_DOCUMENT_10 (dtype: numeric)
FLAG_DOCUMENT_11 (dtype: numeric)
FLAG_DOCUMENT_12 (dtype: numeric)
FLAG_DOCUMENT_13 (dtype: numeric)
FLAG_DOCUMENT_14 (dtype: numeric)
FLAG_DOCUMENT_15 (dtype: numeric)
FLAG_DOCUMENT_16 (dtype: numeric)
FLAG_DOCUMENT_17 (dtype: numeric)
FLAG_DOCUMENT_18 (dtype: numeric)
FLAG_DOCUMENT_19 (dtype: numeric)
FLAG_DOCUMENT_20 (dtype: numeric)
FLAG_DOCUMENT_21 (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_HOUR (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_DAY (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_WEEK (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_MON (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_QRT (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_YEAR (dtype: numeric)
Test (dtype: boolean)
Shape:
(Rows: 356255, Columns: 123)
Unfortunately it looks like some of the data types are incorrect! Many of the FLAG_* columns should be boolean, not numeric. Featuretools automatically infers the datatype of each column from the datatype in the pandas dataframe which was input to Featuretools. To correct this problem, we can either change the datatype in the pandas dataframe, or we can manually set the datatype in Featuretools. Here we’ll do the same operation as before (add the applications dataframe as an entity), but this time we’ll manually set the datatype of certain columns. In addition to the boolean datatype, there are also Index, Datetime, Numeric, Categorical, Ordinal, Text, LatLong, and other Featuretools datatypes.
# Featuretools datatypes
BOOL = ft.variable_types.Boolean
# Manually define datatypes in app dataframe
variable_types = {
'FLAG_MOBIL': BOOL,
'FLAG_EMP_PHONE': BOOL,
'FLAG_WORK_PHONE': BOOL,
'FLAG_CONT_MOBILE': BOOL,
'FLAG_PHONE': BOOL,
'FLAG_EMAIL': BOOL,
'REG_REGION_NOT_LIVE_REGION': BOOL,
'REG_REGION_NOT_WORK_REGION': BOOL,
'LIVE_REGION_NOT_WORK_REGION': BOOL,
'REG_CITY_NOT_LIVE_CITY': BOOL,
'REG_CITY_NOT_WORK_CITY': BOOL,
'LIVE_CITY_NOT_WORK_CITY': BOOL,
'FLAG_DOCUMENT_2': BOOL,
'FLAG_DOCUMENT_3': BOOL,
'FLAG_DOCUMENT_4': BOOL,
'FLAG_DOCUMENT_5': BOOL,
'FLAG_DOCUMENT_6': BOOL,
'FLAG_DOCUMENT_7': BOOL,
'FLAG_DOCUMENT_8': BOOL,
'FLAG_DOCUMENT_9': BOOL,
'FLAG_DOCUMENT_10': BOOL,
'FLAG_DOCUMENT_11': BOOL,
'FLAG_DOCUMENT_12': BOOL,
'FLAG_DOCUMENT_13': BOOL,
'FLAG_DOCUMENT_14': BOOL,
'FLAG_DOCUMENT_15': BOOL,
'FLAG_DOCUMENT_16': BOOL,
'FLAG_DOCUMENT_17': BOOL,
'FLAG_DOCUMENT_18': BOOL,
'FLAG_DOCUMENT_19': BOOL,
'FLAG_DOCUMENT_20': BOOL,
'FLAG_DOCUMENT_21': BOOL,
}
# Add dataframe to entityset, using manual datatypes
es = es.entity_from_dataframe(entity_id='applications',
dataframe=app,
index='SK_ID_CURR',
variable_types=variable_types)
And now when we view the column datatypes in the applications entity, they have the correct boolean type.
es['applications']
Entity: applications
Variables:
SK_ID_CURR (dtype: index)
TARGET (dtype: numeric)
NAME_CONTRACT_TYPE (dtype: categorical)
CODE_GENDER (dtype: categorical)
FLAG_OWN_CAR (dtype: categorical)
FLAG_OWN_REALTY (dtype: categorical)
CNT_CHILDREN (dtype: numeric)
AMT_INCOME_TOTAL (dtype: numeric)
AMT_CREDIT (dtype: numeric)
AMT_ANNUITY (dtype: numeric)
AMT_GOODS_PRICE (dtype: numeric)
NAME_TYPE_SUITE (dtype: categorical)
NAME_INCOME_TYPE (dtype: categorical)
NAME_EDUCATION_TYPE (dtype: categorical)
NAME_FAMILY_STATUS (dtype: categorical)
NAME_HOUSING_TYPE (dtype: categorical)
REGION_POPULATION_RELATIVE (dtype: numeric)
DAYS_BIRTH (dtype: numeric)
DAYS_EMPLOYED (dtype: numeric)
DAYS_REGISTRATION (dtype: numeric)
DAYS_ID_PUBLISH (dtype: numeric)
OWN_CAR_AGE (dtype: numeric)
OCCUPATION_TYPE (dtype: categorical)
CNT_FAM_MEMBERS (dtype: numeric)
REGION_RATING_CLIENT (dtype: numeric)
REGION_RATING_CLIENT_W_CITY (dtype: numeric)
WEEKDAY_APPR_PROCESS_START (dtype: categorical)
HOUR_APPR_PROCESS_START (dtype: numeric)
ORGANIZATION_TYPE (dtype: categorical)
EXT_SOURCE_1 (dtype: numeric)
EXT_SOURCE_2 (dtype: numeric)
EXT_SOURCE_3 (dtype: numeric)
APARTMENTS_AVG (dtype: numeric)
BASEMENTAREA_AVG (dtype: numeric)
YEARS_BEGINEXPLUATATION_AVG (dtype: numeric)
YEARS_BUILD_AVG (dtype: numeric)
COMMONAREA_AVG (dtype: numeric)
ELEVATORS_AVG (dtype: numeric)
ENTRANCES_AVG (dtype: numeric)
FLOORSMAX_AVG (dtype: numeric)
FLOORSMIN_AVG (dtype: numeric)
LANDAREA_AVG (dtype: numeric)
LIVINGAPARTMENTS_AVG (dtype: numeric)
LIVINGAREA_AVG (dtype: numeric)
NONLIVINGAPARTMENTS_AVG (dtype: numeric)
NONLIVINGAREA_AVG (dtype: numeric)
APARTMENTS_MODE (dtype: numeric)
BASEMENTAREA_MODE (dtype: numeric)
YEARS_BEGINEXPLUATATION_MODE (dtype: numeric)
YEARS_BUILD_MODE (dtype: numeric)
COMMONAREA_MODE (dtype: numeric)
ELEVATORS_MODE (dtype: numeric)
ENTRANCES_MODE (dtype: numeric)
FLOORSMAX_MODE (dtype: numeric)
FLOORSMIN_MODE (dtype: numeric)
LANDAREA_MODE (dtype: numeric)
LIVINGAPARTMENTS_MODE (dtype: numeric)
LIVINGAREA_MODE (dtype: numeric)
NONLIVINGAPARTMENTS_MODE (dtype: numeric)
NONLIVINGAREA_MODE (dtype: numeric)
APARTMENTS_MEDI (dtype: numeric)
BASEMENTAREA_MEDI (dtype: numeric)
YEARS_BEGINEXPLUATATION_MEDI (dtype: numeric)
YEARS_BUILD_MEDI (dtype: numeric)
COMMONAREA_MEDI (dtype: numeric)
ELEVATORS_MEDI (dtype: numeric)
ENTRANCES_MEDI (dtype: numeric)
FLOORSMAX_MEDI (dtype: numeric)
FLOORSMIN_MEDI (dtype: numeric)
LANDAREA_MEDI (dtype: numeric)
LIVINGAPARTMENTS_MEDI (dtype: numeric)
LIVINGAREA_MEDI (dtype: numeric)
NONLIVINGAPARTMENTS_MEDI (dtype: numeric)
NONLIVINGAREA_MEDI (dtype: numeric)
FONDKAPREMONT_MODE (dtype: categorical)
HOUSETYPE_MODE (dtype: categorical)
TOTALAREA_MODE (dtype: numeric)
WALLSMATERIAL_MODE (dtype: categorical)
EMERGENCYSTATE_MODE (dtype: categorical)
OBS_30_CNT_SOCIAL_CIRCLE (dtype: numeric)
DEF_30_CNT_SOCIAL_CIRCLE (dtype: numeric)
OBS_60_CNT_SOCIAL_CIRCLE (dtype: numeric)
DEF_60_CNT_SOCIAL_CIRCLE (dtype: numeric)
DAYS_LAST_PHONE_CHANGE (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_HOUR (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_DAY (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_WEEK (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_MON (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_QRT (dtype: numeric)
AMT_REQ_CREDIT_BUREAU_YEAR (dtype: numeric)
Test (dtype: boolean)
FLAG_MOBIL (dtype: boolean)
FLAG_EMP_PHONE (dtype: boolean)
FLAG_WORK_PHONE (dtype: boolean)
FLAG_CONT_MOBILE (dtype: boolean)
FLAG_PHONE (dtype: boolean)
FLAG_EMAIL (dtype: boolean)
REG_REGION_NOT_LIVE_REGION (dtype: boolean)
REG_REGION_NOT_WORK_REGION (dtype: boolean)
LIVE_REGION_NOT_WORK_REGION (dtype: boolean)
REG_CITY_NOT_LIVE_CITY (dtype: boolean)
REG_CITY_NOT_WORK_CITY (dtype: boolean)
LIVE_CITY_NOT_WORK_CITY (dtype: boolean)
FLAG_DOCUMENT_2 (dtype: boolean)
FLAG_DOCUMENT_3 (dtype: boolean)
FLAG_DOCUMENT_4 (dtype: boolean)
FLAG_DOCUMENT_5 (dtype: boolean)
FLAG_DOCUMENT_6 (dtype: boolean)
FLAG_DOCUMENT_7 (dtype: boolean)
FLAG_DOCUMENT_8 (dtype: boolean)
FLAG_DOCUMENT_9 (dtype: boolean)
FLAG_DOCUMENT_10 (dtype: boolean)
FLAG_DOCUMENT_11 (dtype: boolean)
FLAG_DOCUMENT_12 (dtype: boolean)
FLAG_DOCUMENT_13 (dtype: boolean)
FLAG_DOCUMENT_14 (dtype: boolean)
FLAG_DOCUMENT_15 (dtype: boolean)
FLAG_DOCUMENT_16 (dtype: boolean)
FLAG_DOCUMENT_17 (dtype: boolean)
FLAG_DOCUMENT_18 (dtype: boolean)
FLAG_DOCUMENT_19 (dtype: boolean)
FLAG_DOCUMENT_20 (dtype: boolean)
FLAG_DOCUMENT_21 (dtype: boolean)
Shape:
(Rows: 356255, Columns: 123)
Now we’ll add the remaining data tables to the entityset. We’ll use index='New' to indicate that there is no index column in the dataframe (which uniquely identifies each row), and a new index should be created.
# Featuretools datatypes
BOOL = ft.variable_types.Boolean
ID = ft.variable_types.Id
# Add bureau dataframe to entityset
es = es.entity_from_dataframe(
entity_id='bureau',
dataframe=bureau,
index='SK_ID_BUREAU',
variable_types={'SK_ID_CURR': ID})
# Add bureau_balance dataframe to entityset
es = es.entity_from_dataframe(
entity_id='bureau_balance',
dataframe=bureau_balance,
index='New',
variable_types={'SK_ID_BUREAU': ID})
# Add cash_balance dataframe to entityset
es = es.entity_from_dataframe(
entity_id='cash_balance',
dataframe=cash_balance,
index='New',
variable_types={'SK_ID_PREV': ID,
'SK_ID_CURR': ID})
# Add card_balance dataframe to entityset
es = es.entity_from_dataframe(
entity_id='card_balance',
dataframe=card_balance,
index='New',
variable_types={'SK_ID_PREV': ID,
'SK_ID_CURR': ID})
# Add prev_app dataframe to entityset
es = es.entity_from_dataframe(
entity_id='prev_app',
dataframe=prev_app,
index='SK_ID_PREV',
variable_types={'SK_ID_CURR': ID,
'NFLAG_LAST_APPL_IN_DAY': BOOL})
# Add payments dataframe to entityset
es = es.entity_from_dataframe(
entity_id='payments',
dataframe=payments,
index='New',
variable_types={'SK_ID_PREV': ID,
'SK_ID_CURR': ID})
Now when we view the entity set, we can see it contains all the dataframes.
es
Entityset: applications
Entities:
applications [Rows: 356255, Columns: 123]
bureau [Rows: 1716428, Columns: 17]
bureau_balance [Rows: 27299925, Columns: 4]
cash_balance [Rows: 10001358, Columns: 9]
card_balance [Rows: 3840312, Columns: 24]
prev_app [Rows: 1670214, Columns: 37]
payments [Rows: 13605401, Columns: 9]
Relationships:
No relationships
The next step is to define the relationships between entities. That is, what columns in a given entity map to which column in some other entity.
# Define relationships between dataframes
relationships = [
# parent_entity parent_variable child_entity child_variable
('applications', 'SK_ID_CURR', 'bureau', 'SK_ID_CURR'),
('bureau', 'SK_ID_BUREAU', 'bureau_balance', 'SK_ID_BUREAU'),
('applications', 'SK_ID_CURR', 'prev_app', 'SK_ID_CURR'),
('applications', 'SK_ID_CURR', 'cash_balance', 'SK_ID_CURR'),
('applications', 'SK_ID_CURR', 'payments', 'SK_ID_CURR'),
('applications', 'SK_ID_CURR', 'card_balance', 'SK_ID_CURR')
]
# Create the relationships
for pe, pv, ce, cv in relationships:
es = es.add_relationship(ft.Relationship(es[pe][pv], es[ce][cv]))
Now when we view our entityset, we can see the relationships between tables and columns that we’ve created.
es
Entityset: applications
Entities:
applications [Rows: 356255, Columns: 123]
bureau [Rows: 1716428, Columns: 17]
bureau_balance [Rows: 27299925, Columns: 4]
cash_balance [Rows: 10001358, Columns: 9]
card_balance [Rows: 3840312, Columns: 24]
prev_app [Rows: 1670214, Columns: 37]
payments [Rows: 13605401, Columns: 9]
Relationships:
bureau.SK_ID_CURR -> applications.SK_ID_CURR
bureau_balance.SK_ID_BUREAU -> bureau.SK_ID_BUREAU
prev_app.SK_ID_CURR -> applications.SK_ID_CURR
cash_balance.SK_ID_CURR -> applications.SK_ID_CURR
payments.SK_ID_CURR -> applications.SK_ID_CURR
card_balance.SK_ID_CURR -> applications.SK_ID_CURR
Next we can define which “feature primitives” we want to use to construct features. First let’s look at a list of all the feature primitives available in Featuretools:
pd.options.display.max_rows = 100
ft.list_primitives()
| name | type | description | |
|---|---|---|---|
| 0 | last | aggregation | Returns the last value. |
| 1 | max | aggregation | Finds the maximum non-null value of a numeric ... |
| 2 | mode | aggregation | Finds the most common element in a categorical... |
| 3 | std | aggregation | Finds the standard deviation of a numeric feat... |
| 4 | min | aggregation | Finds the minimum non-null value of a numeric ... |
| 5 | mean | aggregation | Computes the average value of a numeric feature. |
| 6 | skew | aggregation | Computes the skewness of a data set. |
| 7 | trend | aggregation | Calculates the slope of the linear trend of va... |
| 8 | sum | aggregation | Counts the number of elements of a numeric or ... |
| 9 | median | aggregation | Finds the median value of any feature with wel... |
| 10 | time_since_last | aggregation | Time since last related instance. |
| 11 | num_true | aggregation | Finds the number of 'True' values in a boolean. |
| 12 | avg_time_between | aggregation | Computes the average time between consecutive ... |
| 13 | percent_true | aggregation | Finds the percent of 'True' values in a boolea... |
| 14 | all | aggregation | Test if all values are 'True'. |
| 15 | n_most_common | aggregation | Finds the N most common elements in a categori... |
| 16 | count | aggregation | Counts the number of non null values. |
| 17 | any | aggregation | Test if any value is 'True'. |
| 18 | num_unique | aggregation | Returns the number of unique categorical varia... |
| 19 | month | transform | Transform a Datetime feature into the month. |
| 20 | negate | transform | Creates a transform feature that negates a fea... |
| 21 | latitude | transform | Returns the first value of the tuple base feat... |
| 22 | cum_min | transform | Calculates the min of previous values of an in... |
| 23 | divide | transform | Creates a transform feature that divides two f... |
| 24 | week | transform | Transform a Datetime feature into the week. |
| 25 | not | transform | For each value of the base feature, negates th... |
| 26 | cum_count | transform | Calculates the number of previous values of an... |
| 27 | hours | transform | Transform a Timedelta feature into the number ... |
| 28 | minute | transform | Transform a Datetime feature into the minute. |
| 29 | subtract | transform | Creates a transform feature that subtracts two... |
| 30 | cum_sum | transform | Calculates the sum of previous values of an in... |
| 31 | days | transform | Transform a Timedelta feature into the number ... |
| 32 | numwords | transform | Returns the words in a given string by countin... |
| 33 | and | transform | For two boolean values, determine if both valu... |
| 34 | weekday | transform | Transform Datetime feature into the boolean of... |
| 35 | time_since_previous | transform | Compute the time since the previous instance. |
| 36 | years | transform | Transform a Timedelta feature into the number ... |
| 37 | days_since | transform | For each value of the base feature, compute th... |
| 38 | is_null | transform | For each value of base feature, return 'True' ... |
| 39 | months | transform | Transform a Timedelta feature into the number ... |
| 40 | longitude | transform | Returns the second value on the tuple base fea... |
| 41 | mod | transform | Creates a transform feature that divides two f... |
| 42 | weeks | transform | Transform a Timedelta feature into the number ... |
| 43 | percentile | transform | For each value of the base feature, determines... |
| 44 | cum_max | transform | Calculates the max of previous values of an in... |
| 45 | second | transform | Transform a Datetime feature into the second. |
| 46 | minutes | transform | Transform a Timedelta feature into the number ... |
| 47 | multiply | transform | Creates a transform feature that multplies two... |
| 48 | diff | transform | Compute the difference between the value of a ... |
| 49 | cum_mean | transform | Calculates the mean of previous values of an i... |
| 50 | year | transform | Transform a Datetime feature into the year. |
| 51 | hour | transform | Transform a Datetime feature into the hour. |
| 52 | add | transform | Creates a transform feature that adds two feat... |
| 53 | or | transform | For two boolean values, determine if one value... |
| 54 | seconds | transform | Transform a Timedelta feature into the number ... |
| 55 | day | transform | Transform a Datetime feature into the day. |
| 56 | characters | transform | Return the characters in a given string. |
| 57 | weekend | transform | Transform Datetime feature into the boolean of... |
| 58 | isin | transform | For each value of the base feature, checks whe... |
| 59 | absolute | transform | Absolute value of base feature. |
| 60 | haversine | transform | Calculate the approximate haversine distance i... |
| 61 | time_since | transform | Calculates time since the cutoff time. |
We’ll use a simple set of feature primitives: just the mean, count, cumulative sum, and number of unique elements for entries in the secondary data files. However, you could use whichever combinations of feature primitives you think will be needed for your problem. You can also simply not pass a list of primitives to use in order to use them all!
# Define which primitives to use
agg_primitives = ['count', 'mean', 'num_unique']
trans_primitives = ['cum_sum']
Finally, we can run deep feature synthesis on our entities given their relationships and a list of feature primitives. This’ll take a while!
# Run deep feature synthesis
dfs_feat, dfs_defs = ft.dfs(entityset=es,
target_entity='applications',
trans_primitives=trans_primitives,
agg_primitives=agg_primitives,
verbose = True,
max_depth=2, n_jobs=2)
Built 218 features
If we take a look at the columns of the dataframe which was returned by Featuretools, we can see that a bunch of features were appended which correspond to our selected feature primitive functions applied to data in the secondary data files which correspond to each row in the main application dataset.
dfs_feat.columns.tolist()
['TARGET',
'NAME_CONTRACT_TYPE',
'CODE_GENDER',
'FLAG_OWN_CAR',
'FLAG_OWN_REALTY',
'CNT_CHILDREN',
'AMT_INCOME_TOTAL',
'AMT_CREDIT',
'AMT_ANNUITY',
'AMT_GOODS_PRICE',
'NAME_TYPE_SUITE',
'NAME_INCOME_TYPE',
'NAME_EDUCATION_TYPE',
'NAME_FAMILY_STATUS',
'NAME_HOUSING_TYPE',
'REGION_POPULATION_RELATIVE',
'DAYS_BIRTH',
'DAYS_EMPLOYED',
'DAYS_REGISTRATION',
'DAYS_ID_PUBLISH',
'OWN_CAR_AGE',
'OCCUPATION_TYPE',
'CNT_FAM_MEMBERS',
'REGION_RATING_CLIENT',
'REGION_RATING_CLIENT_W_CITY',
'WEEKDAY_APPR_PROCESS_START',
'HOUR_APPR_PROCESS_START',
'ORGANIZATION_TYPE',
'EXT_SOURCE_1',
'EXT_SOURCE_2',
'EXT_SOURCE_3',
'APARTMENTS_AVG',
'BASEMENTAREA_AVG',
'YEARS_BEGINEXPLUATATION_AVG',
'YEARS_BUILD_AVG',
'COMMONAREA_AVG',
'ELEVATORS_AVG',
'ENTRANCES_AVG',
'FLOORSMAX_AVG',
'FLOORSMIN_AVG',
'LANDAREA_AVG',
'LIVINGAPARTMENTS_AVG',
'LIVINGAREA_AVG',
'NONLIVINGAPARTMENTS_AVG',
'NONLIVINGAREA_AVG',
'APARTMENTS_MODE',
'BASEMENTAREA_MODE',
'YEARS_BEGINEXPLUATATION_MODE',
'YEARS_BUILD_MODE',
'COMMONAREA_MODE',
'ELEVATORS_MODE',
'ENTRANCES_MODE',
'FLOORSMAX_MODE',
'FLOORSMIN_MODE',
'LANDAREA_MODE',
'LIVINGAPARTMENTS_MODE',
'LIVINGAREA_MODE',
'NONLIVINGAPARTMENTS_MODE',
'NONLIVINGAREA_MODE',
'APARTMENTS_MEDI',
'BASEMENTAREA_MEDI',
'YEARS_BEGINEXPLUATATION_MEDI',
'YEARS_BUILD_MEDI',
'COMMONAREA_MEDI',
'ELEVATORS_MEDI',
'ENTRANCES_MEDI',
'FLOORSMAX_MEDI',
'FLOORSMIN_MEDI',
'LANDAREA_MEDI',
'LIVINGAPARTMENTS_MEDI',
'LIVINGAREA_MEDI',
'NONLIVINGAPARTMENTS_MEDI',
'NONLIVINGAREA_MEDI',
'FONDKAPREMONT_MODE',
'HOUSETYPE_MODE',
'TOTALAREA_MODE',
'WALLSMATERIAL_MODE',
'EMERGENCYSTATE_MODE',
'OBS_30_CNT_SOCIAL_CIRCLE',
'DEF_30_CNT_SOCIAL_CIRCLE',
'OBS_60_CNT_SOCIAL_CIRCLE',
'DEF_60_CNT_SOCIAL_CIRCLE',
'DAYS_LAST_PHONE_CHANGE',
'AMT_REQ_CREDIT_BUREAU_HOUR',
'AMT_REQ_CREDIT_BUREAU_DAY',
'AMT_REQ_CREDIT_BUREAU_WEEK',
'AMT_REQ_CREDIT_BUREAU_MON',
'AMT_REQ_CREDIT_BUREAU_QRT',
'AMT_REQ_CREDIT_BUREAU_YEAR',
'Test',
'FLAG_MOBIL',
'FLAG_EMP_PHONE',
'FLAG_WORK_PHONE',
'FLAG_CONT_MOBILE',
'FLAG_PHONE',
'FLAG_EMAIL',
'REG_REGION_NOT_LIVE_REGION',
'REG_REGION_NOT_WORK_REGION',
'LIVE_REGION_NOT_WORK_REGION',
'REG_CITY_NOT_LIVE_CITY',
'REG_CITY_NOT_WORK_CITY',
'LIVE_CITY_NOT_WORK_CITY',
'FLAG_DOCUMENT_2',
'FLAG_DOCUMENT_3',
'FLAG_DOCUMENT_4',
'FLAG_DOCUMENT_5',
'FLAG_DOCUMENT_6',
'FLAG_DOCUMENT_7',
'FLAG_DOCUMENT_8',
'FLAG_DOCUMENT_9',
'FLAG_DOCUMENT_10',
'FLAG_DOCUMENT_11',
'FLAG_DOCUMENT_12',
'FLAG_DOCUMENT_13',
'FLAG_DOCUMENT_14',
'FLAG_DOCUMENT_15',
'FLAG_DOCUMENT_16',
'FLAG_DOCUMENT_17',
'FLAG_DOCUMENT_18',
'FLAG_DOCUMENT_19',
'FLAG_DOCUMENT_20',
'FLAG_DOCUMENT_21',
'COUNT(payments)',
'MEAN(payments.NUM_INSTALMENT_VERSION)',
'MEAN(payments.NUM_INSTALMENT_NUMBER)',
'MEAN(payments.DAYS_INSTALMENT)',
'MEAN(payments.DAYS_ENTRY_PAYMENT)',
'MEAN(payments.AMT_INSTALMENT)',
'MEAN(payments.AMT_PAYMENT)',
'NUM_UNIQUE(payments.SK_ID_PREV)',
'COUNT(bureau)',
'MEAN(bureau.DAYS_CREDIT)',
'MEAN(bureau.CREDIT_DAY_OVERDUE)',
'MEAN(bureau.DAYS_CREDIT_ENDDATE)',
'MEAN(bureau.DAYS_ENDDATE_FACT)',
'MEAN(bureau.AMT_CREDIT_MAX_OVERDUE)',
'MEAN(bureau.CNT_CREDIT_PROLONG)',
'MEAN(bureau.AMT_CREDIT_SUM)',
'MEAN(bureau.AMT_CREDIT_SUM_DEBT)',
'MEAN(bureau.AMT_CREDIT_SUM_LIMIT)',
'MEAN(bureau.AMT_CREDIT_SUM_OVERDUE)',
'MEAN(bureau.DAYS_CREDIT_UPDATE)',
'MEAN(bureau.AMT_ANNUITY)',
'NUM_UNIQUE(bureau.CREDIT_ACTIVE)',
'NUM_UNIQUE(bureau.CREDIT_CURRENCY)',
'NUM_UNIQUE(bureau.CREDIT_TYPE)',
'COUNT(cash_balance)',
'MEAN(cash_balance.MONTHS_BALANCE)',
'MEAN(cash_balance.CNT_INSTALMENT)',
'MEAN(cash_balance.CNT_INSTALMENT_FUTURE)',
'MEAN(cash_balance.SK_DPD)',
'MEAN(cash_balance.SK_DPD_DEF)',
'NUM_UNIQUE(cash_balance.NAME_CONTRACT_STATUS)',
'NUM_UNIQUE(cash_balance.SK_ID_PREV)',
'COUNT(prev_app)',
'MEAN(prev_app.AMT_ANNUITY)',
'MEAN(prev_app.AMT_APPLICATION)',
'MEAN(prev_app.AMT_CREDIT)',
'MEAN(prev_app.AMT_DOWN_PAYMENT)',
'MEAN(prev_app.AMT_GOODS_PRICE)',
'MEAN(prev_app.HOUR_APPR_PROCESS_START)',
'MEAN(prev_app.RATE_DOWN_PAYMENT)',
'MEAN(prev_app.RATE_INTEREST_PRIMARY)',
'MEAN(prev_app.RATE_INTEREST_PRIVILEGED)',
'MEAN(prev_app.DAYS_DECISION)',
'MEAN(prev_app.SELLERPLACE_AREA)',
'MEAN(prev_app.CNT_PAYMENT)',
'MEAN(prev_app.DAYS_FIRST_DRAWING)',
'MEAN(prev_app.DAYS_FIRST_DUE)',
'MEAN(prev_app.DAYS_LAST_DUE_1ST_VERSION)',
'MEAN(prev_app.DAYS_LAST_DUE)',
'MEAN(prev_app.DAYS_TERMINATION)',
'MEAN(prev_app.NFLAG_INSURED_ON_APPROVAL)',
'NUM_UNIQUE(prev_app.NAME_CONTRACT_TYPE)',
'NUM_UNIQUE(prev_app.WEEKDAY_APPR_PROCESS_START)',
'NUM_UNIQUE(prev_app.FLAG_LAST_APPL_PER_CONTRACT)',
'NUM_UNIQUE(prev_app.NAME_CASH_LOAN_PURPOSE)',
'NUM_UNIQUE(prev_app.NAME_CONTRACT_STATUS)',
'NUM_UNIQUE(prev_app.NAME_PAYMENT_TYPE)',
'NUM_UNIQUE(prev_app.CODE_REJECT_REASON)',
'NUM_UNIQUE(prev_app.NAME_TYPE_SUITE)',
'NUM_UNIQUE(prev_app.NAME_CLIENT_TYPE)',
'NUM_UNIQUE(prev_app.NAME_GOODS_CATEGORY)',
'NUM_UNIQUE(prev_app.NAME_PORTFOLIO)',
'NUM_UNIQUE(prev_app.NAME_PRODUCT_TYPE)',
'NUM_UNIQUE(prev_app.CHANNEL_TYPE)',
'NUM_UNIQUE(prev_app.NAME_SELLER_INDUSTRY)',
'NUM_UNIQUE(prev_app.NAME_YIELD_GROUP)',
'NUM_UNIQUE(prev_app.PRODUCT_COMBINATION)',
'COUNT(card_balance)',
'MEAN(card_balance.MONTHS_BALANCE)',
'MEAN(card_balance.AMT_BALANCE)',
'MEAN(card_balance.AMT_CREDIT_LIMIT_ACTUAL)',
'MEAN(card_balance.AMT_DRAWINGS_ATM_CURRENT)',
'MEAN(card_balance.AMT_DRAWINGS_CURRENT)',
'MEAN(card_balance.AMT_DRAWINGS_OTHER_CURRENT)',
'MEAN(card_balance.AMT_DRAWINGS_POS_CURRENT)',
'MEAN(card_balance.AMT_INST_MIN_REGULARITY)',
'MEAN(card_balance.AMT_PAYMENT_CURRENT)',
'MEAN(card_balance.AMT_PAYMENT_TOTAL_CURRENT)',
'MEAN(card_balance.AMT_RECEIVABLE_PRINCIPAL)',
'MEAN(card_balance.AMT_RECIVABLE)',
'MEAN(card_balance.AMT_TOTAL_RECEIVABLE)',
'MEAN(card_balance.CNT_DRAWINGS_ATM_CURRENT)',
'MEAN(card_balance.CNT_DRAWINGS_CURRENT)',
'MEAN(card_balance.CNT_DRAWINGS_OTHER_CURRENT)',
'MEAN(card_balance.CNT_DRAWINGS_POS_CURRENT)',
'MEAN(card_balance.CNT_INSTALMENT_MATURE_CUM)',
'MEAN(card_balance.SK_DPD)',
'MEAN(card_balance.SK_DPD_DEF)',
'NUM_UNIQUE(card_balance.NAME_CONTRACT_STATUS)',
'NUM_UNIQUE(card_balance.SK_ID_PREV)',
'COUNT(bureau_balance)',
'MEAN(bureau_balance.MONTHS_BALANCE)',
'NUM_UNIQUE(bureau_balance.STATUS)',
'MEAN(bureau.COUNT(bureau_balance))',
'MEAN(bureau.MEAN(bureau_balance.MONTHS_BALANCE))',
'MEAN(bureau.NUM_UNIQUE(bureau_balance.STATUS))']
Now that we’ve generated a bunch of features, we should make sure to remove ones which don’t carry any information. Featuretools includes a function to remove features which are entirely NULLs or only have one class, etc.
# Remove low information features
dfs_feat = selection.remove_low_information_features(dfs_feat)
In some cases it might also be a good idea to do further feature selection at this point, by, say, removing features which have low mutual information with the target variable (loan default).
Predictions from Generated Features
Now that we’ve generated features using Featuretools, we can use those generated features in a predictive model. First, we would have to perform feature encoding on our generated features. See my other post on encoding features of this dataset. Then, we have to split our features back into training and test datasets, and remove the indicator columns.
# Split data back into test + train
train = dfs_feat.loc[~app['Test'], :].copy()
test = dfs_feat.loc[app['Test'], :].copy()
# Ensure all data is stored as floats
train = train.astype(np.float32)
test = test.astype(np.float32)
# Target labels
train_y = train['TARGET']
# Remove test/train indicator column and target column
train.drop(columns=['Test', 'TARGET'], inplace=True)
test.drop(columns=['Test', 'TARGET'], inplace=True)
Then we can run a predictive model, such as LightGBM, on the generated features to predict how likely applicants are to default on their loans.
# Classification pipeline w/ LightGBM
lgbm_pipeline = Pipeline([
('scaler', RobustScaler()),
('imputer', SimpleImputer(strategy='median')),
('classifier', CalibratedClassifierCV(
base_estimator=LGBMClassifier(),
method='isotonic'))
])
# Fit to training data
lgbm_fit = lgbm_pipeline.fit(train, train_y)
# Predict loan default probabilities of test data
test_pred = lgbm_fit.predict_proba(test)
# Save predictions to file
df_out = pd.DataFrame()
df_out['SK_ID_CURR'] = test.index
df_out['TARGET'] = test_pred[:,1]
df_out.to_csv('test_predictions.csv', index=False)
Running out of Memory
The downside of Featuretools is that is isn’t generating features all that intelligently - it simply generates features by applying all the feature primitives to all the features in secondary datasets recursively. This means that the number of features which are generated can be huge! When dealing with large datasets, this means that the feature generation process might take up more memory than is available on a personal computer. If you run out of memory, you can always run featuretools on an Amazon Web Services EC2 instance which has enough memory, such as the r5 class of instances.